PPO Reinforcement Learning for Quadruped Locomotion
Trained a robust locomotion policy for the Unitree Go2 quadruped robot within the Isaac Lab physics simulator.
PPO Reinforcement Learning for Quadruped Locomotion
Overview
Trained a robust locomotion policy for the Unitree Go2 quadruped robot within the Isaac Lab physics simulator.
Project Overview
This project centered on training a robust locomotion policy for the Unitree Go2 quadruped robot within the Isaac Lab physics simulator. Utilizing Proximal Policy Optimization (PPO)—a reinforcement learning algorithm that stabilizes training by limiting how much the policy can change per update—the goal was to evolve a deliberately weak baseline policy into a highly capable walking and trotting gait.
Through principled reward shaping and regularization strategies, the policy was optimized for smooth footfall timing, base height maintenance, and accurate tracking of forward, lateral, and yaw velocity commands. The model’s capabilities were further pushed by testing additional objectives, including bipedal walking and ensuring robust gait stability across procedurally generated, uneven terrain.
Quadruped navigating uneven terrain
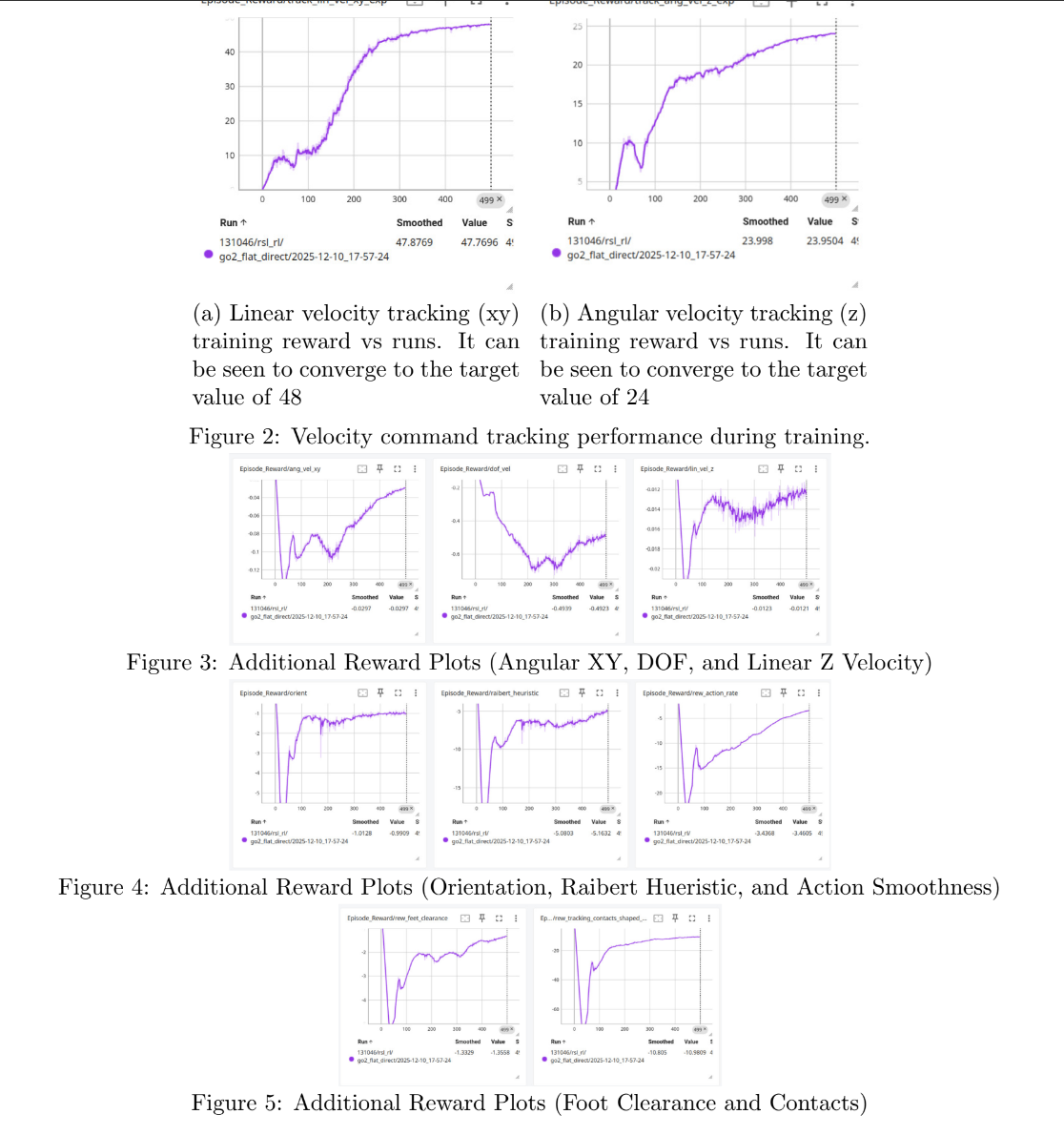
Training reward and convergence plots