Residual Reinforcement Learning for VQ-BET Fine-Tuning
Improving grasp accuracy of a pre-trained VQ-BET base policy by layering a residual RL component trained via Soft Actor-Critic (SAC).
Residual Reinforcement Learning for VQ-BET Fine-Tuning
Overview
Improving grasp accuracy of a pre-trained VQ-BET base policy by layering a residual RL component trained via Soft Actor-Critic (SAC).
Project Overview
This ongoing research at the GRAIL Lab (NYU Courant) seeks to close the sim-to-real gap for robotic manipulation. The core objective was to improve the grasp accuracy of a pre-trained VQ-BET base policy by layering a residual reinforcement learning component trained via Soft Actor-Critic (SAC) optimizations.
Technical Details
Initial training occurred in a highly augmented visual simulation environment, followed by real-world fine-tuning using an auto-reset data collection setup with an XARM in a green-screen cage. The methodology incorporated offline RL critic initialization (evaluating Conservative Q-Learning and Implicit Q-Learning) alongside buffer mixing strategies. Furthermore, I implemented Low-Rank Adaptation (LoRA) and rejection-sampling-based iterative fine-tuning to continuously augment the trajectory data and improve corrective behaviors.
Policy Evaluation
Training in simulated environments
Residual behavior adjustments
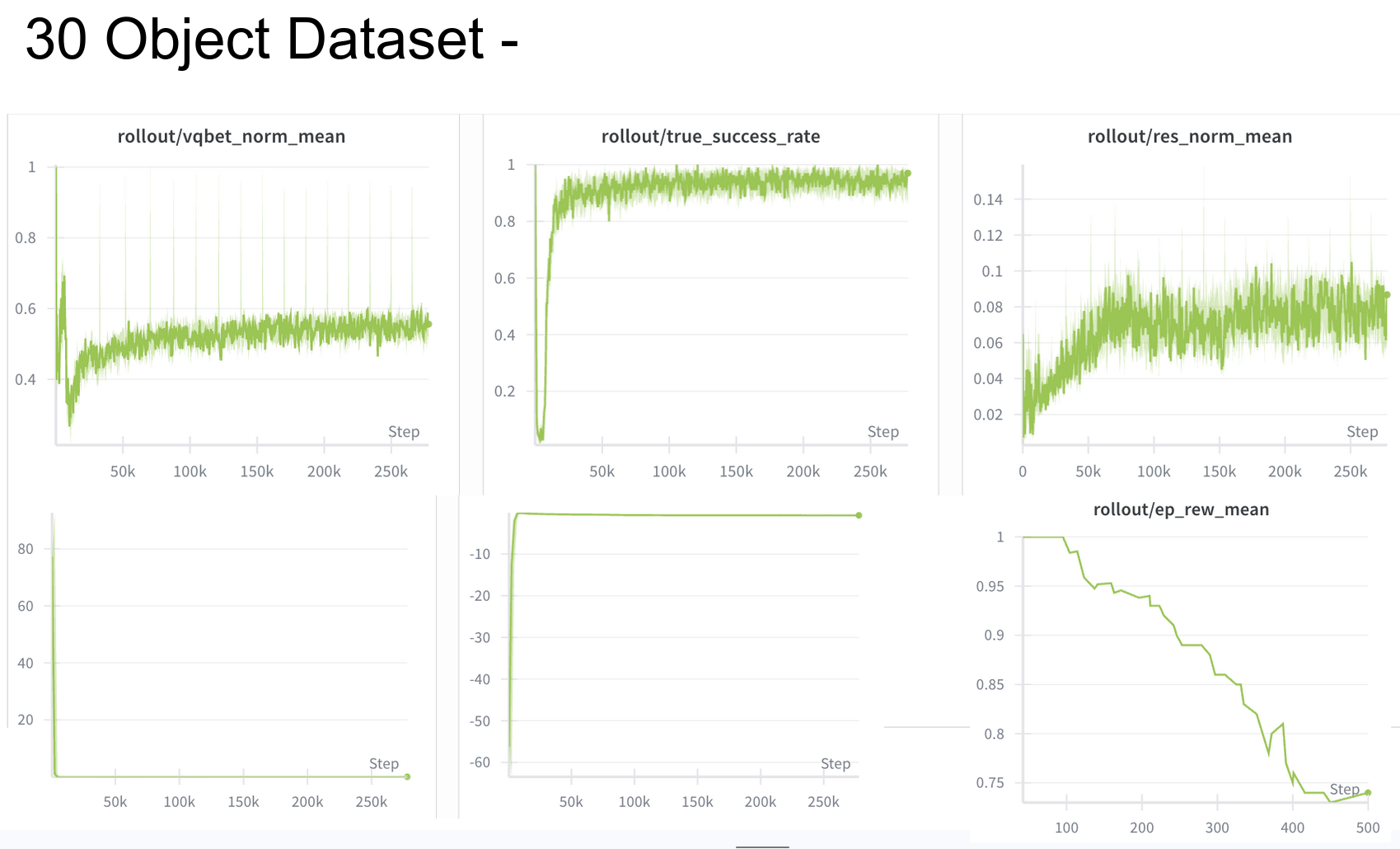
Loss and Reward Plots
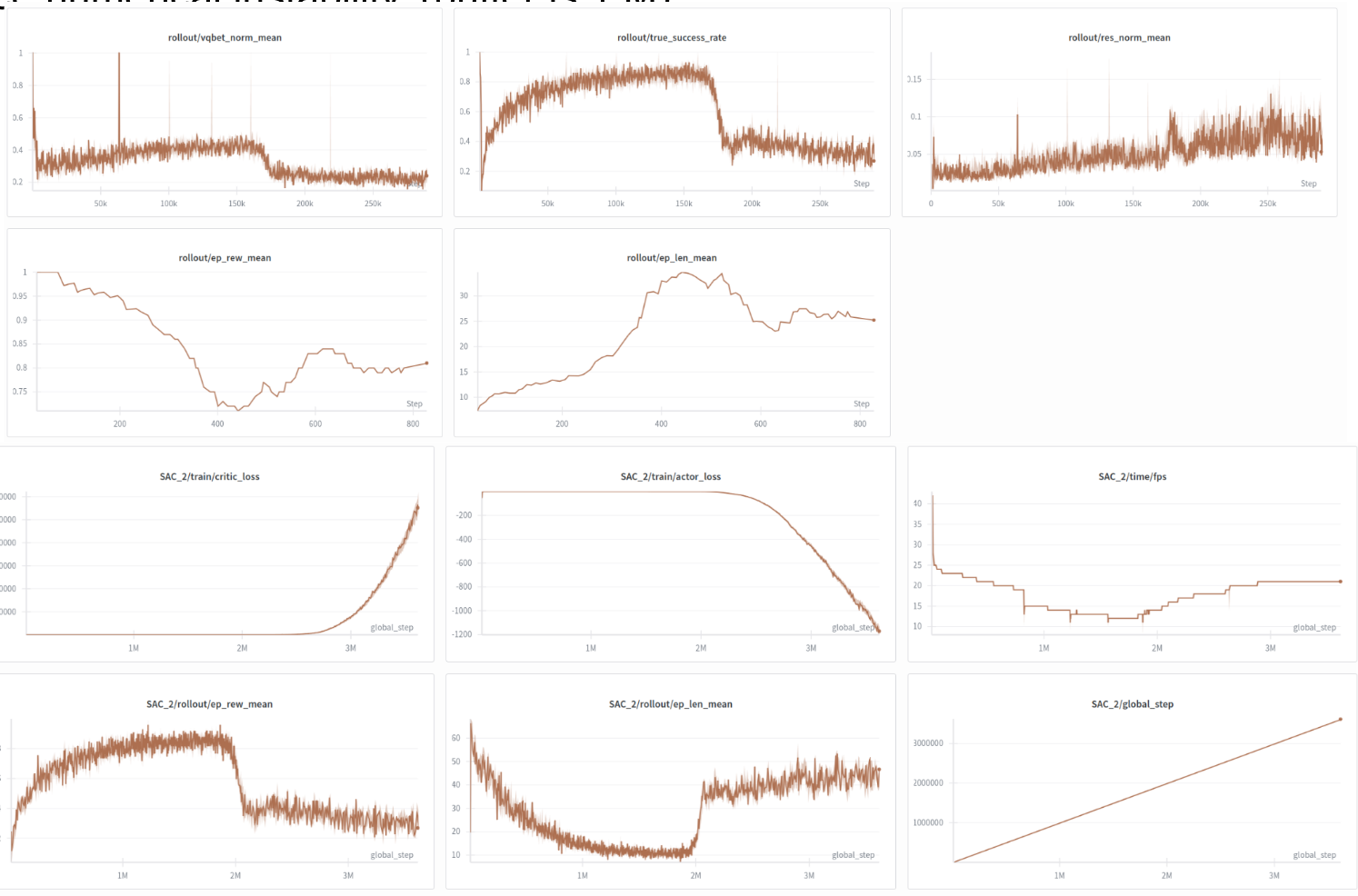
Training Metrics